Build and Scale Faster
150+ products shipped for startups and enterprises by engineers focused on real outcomes.
"Their ability to quickly understand an unfamiliar use case and respond creatively to it is impressive."

Anonymous
Executive, Pured Disc Golf
"TechnBrains resolved challenges efficiently and turned my vision into a solid, functional product with a strong foundation."

Jalen Gibbs
Founder, STREAMLINE LIVE
"The talent they provided was solid, but more importantly, they were quick to align with our way of working."

Nancy Snyder
Managing Director, MimeCast
Our trusted clients

Start Your Product Journey Today
Turn your idea into a working product. Share a few details and we'll help define the roadmap, timeline, and execution approach.
Uncategorized
AI Hallucinations in 2026: Which LLM Hallucinates the Most While Coding?
AI hallucinations in software are hardest to catch when the code looks correct. It may compile, follow the expected structure, and explain itself clearly. The risk appears later, when review exposes a missing security check, shallow test coverage, false assumption, or unfinished business logic. In METR’s early-2025 trial, experienced open-source developers expected AI tools to reduce task time by 24%....
Last update date: Jun 30, 2026
AI hallucinations in software are hardest to catch when the code looks correct.
It may compile, follow the expected structure, and explain itself clearly. The risk appears later, when review exposes a missing security check, shallow test coverage, false assumption, or unfinished business logic.
In METR’s early-2025 trial, experienced open-source developers expected AI tools to reduce task time by 24%. Instead, task time increased by 19%. The added cost came from verification.
TechnBrains tested seven LLMs across four coding tasks and scored each output using the same hallucination-risk framework: Claude Sonnet 4.6 Max, Gemini 3.5 Flash, Gemini 3.1 Pro, GLM, Kimi K2.6 Instant, MiniMax M3, and Codex 5.5 Medium.
These are the LLMs our AI development team uses in real workflows, but final validation still sits with engineers before code moves toward production.
Quick Verdict
GLM had the highest average AI hallucination risk score in our test. Kimi was the riskiest in implementation-heavy tasks, scoring 6 out of 10 in both the Next.js S3 upload and the password reset. Claude had the lowest overall risk. MiniMax was the strongest non-Claude performer.
The table below shows each model’s hallucination-risk score across all four coding tests. Lower score means lower risk.
| Model | Exact version | R1 Stripe | R2 Next.js S3 | R3 Password reset | R4 Jest tests | Average | Overall verdict |
| Claude | Sonnet 4.6 Max | 2 | 2 | 1.5 | 1.5 | 1.75 | Lowest overall hallucination risk |
| MiniMax | MiniMax M3 | 2 | 2.5 | 1.5 | 1.5 | 1.88 | Strongest non-Claude performer |
| Codex | 5.5 Medium | 2.5 | 2.5 | 3 | 3 | 2.75 | Clean and practical, less deep than the top models |
| Gemini 3.1 Pro | Gemini 3.1 Pro | 4 | 3.5 | 2.5 | 3.5 | 3.38 | More reliable than Gemini 3.5 Flash overall |
| Gemini 3.5 Flash | Gemini 3.5 Flash | 2.5 | 4 | 4 | 5 | 3.88 | Fast and clean, weaker depth |
| Kimi | K2.6 Instant | 3 | 6 | 6 | 2 | 4.25 | Strong in test coverage, risky in implementation-heavy tasks |
| GLM | Not visible | 5 | 4 | 5 | 3.5 | 4.38 | Highest average hallucination risk |
What Is an AI Hallucination?
An AI coding hallucination happens when a model presents false, unsupported, or incomplete code behavior as if it works.
That can mean an invented SDK method, a fake package, the wrong framework pattern, a non-existent config option, or a security claim the code does not actually support.
A normal bug uses a real tool incorrectly. An AI hallucination often invents the tool, behavior, or production safety around it.
In practice, this can look like “production-ready” code with TODO business logic, a password reset flow that claims token hashing but stores raw tokens, a test suite that claims full coverage while missing combined logic, or a webhook that returns success before processing is complete.
That is why AI-built prototypes need engineering review before they become real products. We observed the same risk when we tested the different AI app builders, where the gap between a working demo and launch-ready software is the main issue.
How We Tested Each LLM for Coding Hallucinations
We ran the same task through each model, reviewed every output by hand, and scored it on the same framework.
- Same prompt for every model, fresh chat each time.
- We did not correct the model mid-test.
- We saved screenshots and full outputs.
- We reviewed each output against the framework: API references, framework patterns, security behavior, test quality, and the confidence gap.
- Where a model ran its own tests, we noted what its screenshots showed.
This is a point-in-time engineering test, not a permanent ranking. Behavior changes with version, settings, context window, tools, retrieval, and prompt design. Scoring runs 0 (no issue) to 10 (confidently wrong, fake, broken, or unsafe), across six factors: fake reference, runtime or implementation risk, framework mismatch, security omission, weak test confidence, and confidence gap.
Round 1: Which LLM Handled Stripe Webhooks Safest?
Claude and MiniMax handled Stripe webhooks safest, while GLM showed the highest risk by acknowledging the webhook before processing was complete.
Prompt We Used: A Node.js Express webhook handler for Stripe subscriptions, with signature verification, required events, environment variables, proper responses, and error handling.
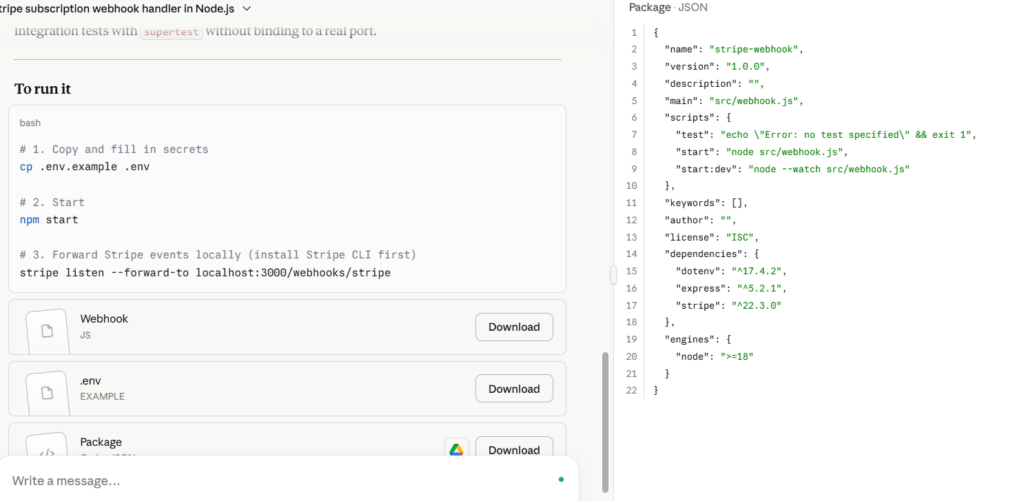
In the Stripe webhook test, none of the models clearly invented a fake Stripe API. The stronger outputs understood raw request body handling and stripe.webhooks.constructEvent(). Claude and MiniMax were strongest because they waited for handler execution before responding and used safer error behavior.
The main risk across the round was confidence inflation: models called webhook shells production-ready while leaving subscription provisioning, access revocation, dunning, database sync, idempotency, monitoring, and retry-safe processing as TODOs.
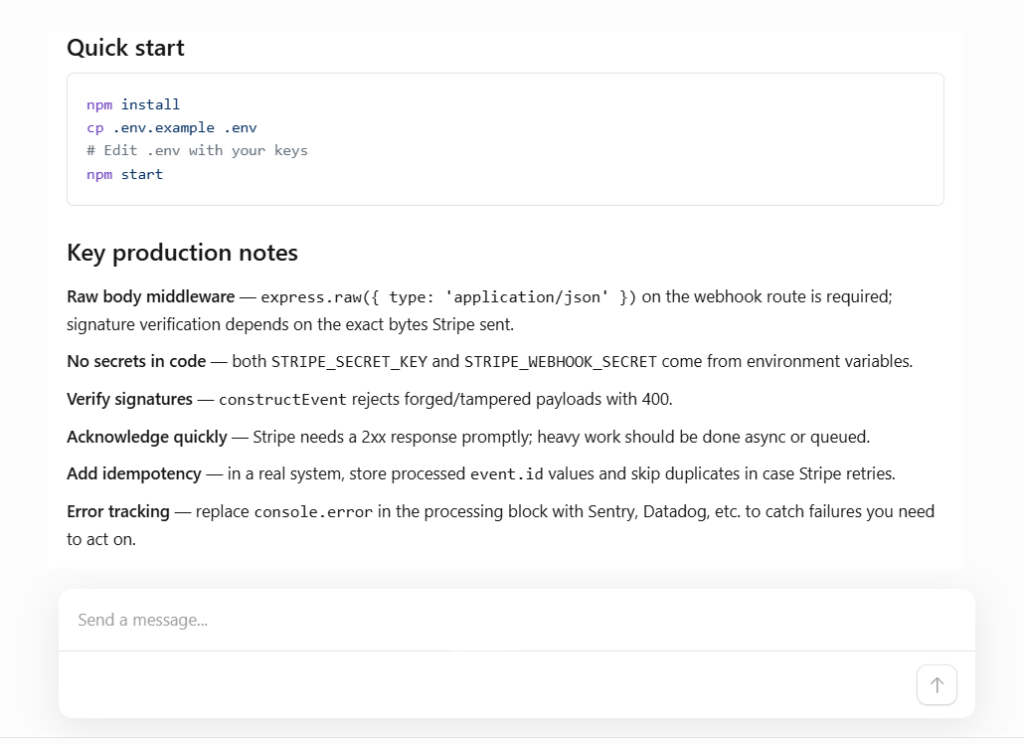
GLM had the riskiest response behavior, acknowledging the webhook before business processing was complete.
| Model | Score | What worked | What failed or looked risky |
| Claude | 2 | Raw-body signature verification, required events, env validation, clean setup | Database and email actions left as placeholders |
| MiniMax | 2 | Env validation at boot, raw body, signature verification, event map, 500 on handler failure | Billing and database operations still TODO |
| Gemini 3.5 Flash | 2.5 | Raw body, signature verification, env vars, correct events | Overclaims readiness; provisioning and payment-failure flows are TODOs |
| Codex | 2.5 | Raw-body handling, signature verification, correct events | Handlers mostly log; uses stripe: latest instead of a pinned version |
| Kimi | 3 | Signature verification, raw-body parsing, event routing | Presented as production-ready while billing and email logic stay TODO |
| Gemini 3.1 Pro | 4 | Understands the core webhook pattern | Mixes install, server code, and .env, which confuses implementation |
| GLM | 5 | Verifies the signature, correct events | Returns 200 OK before processing finishes; failed work can be silently lost |
Lesson: Round 1 revealed no fake Stripe APIs. The risk was confidence inflation: shells called production-ready while idempotency, retries, monitoring, and persistence were missing.
Round 2: Which LLM Hallucinates the Most When Building a Safe Next.js S3 Upload Route?
Kimi had the highest risk in this round because it added a fragile manual parser instead of using the App Router’s built-in
request.formData() pattern. Prompt We Used: A Next.js TypeScript App Router route that accepts JPG, PNG, and WebP only, limits size to 5MB, uploads to S3, returns the file URL, uses environment variables, and avoids credential exposure.
No model fell back to the old Pages Router. Every model put the route under app/api/upload/route.ts. The differences were in production safety. Claude, MiniMax, and Codex produced the cleanest implementations.
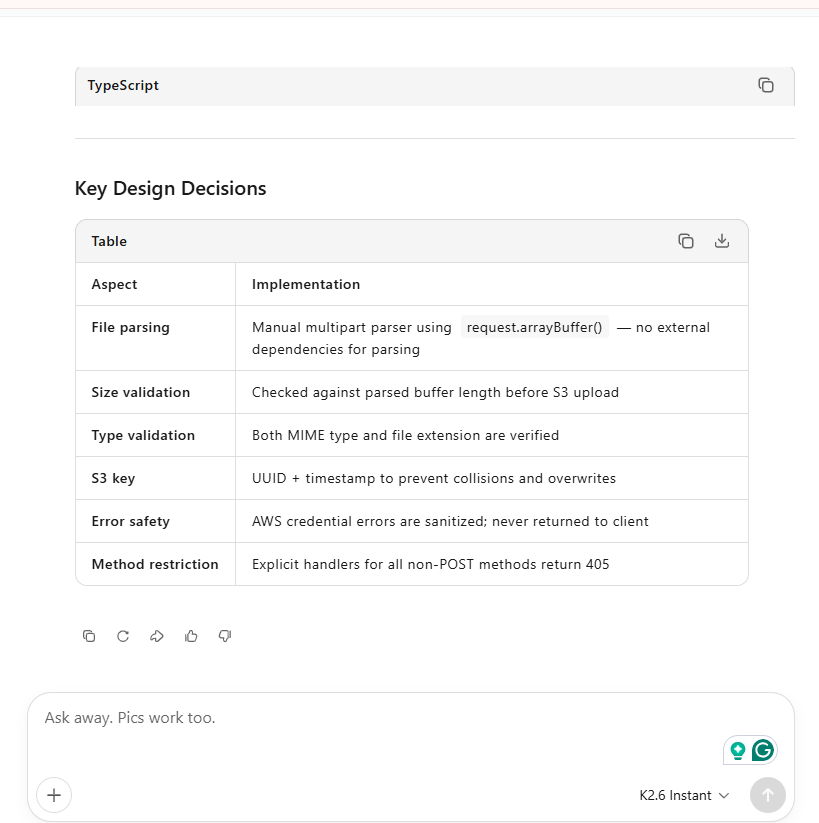
Gemini 3.5 Flash and GLM gave workable but thinner outputs with weak environment validation. Kimi carried the highest risk because it hand-rolled a fragile multipart parser even though App Router supports request.formData(). Between the Gemini models, 3.1 Pro edged 3.5 Flash, which leaned on empty-string credential fallbacks.
| Model | Score | What worked | What failed or looked risky |
| Claude | 2 | App Router, formData(), MIME and 5MB validation, env vars, S3 upload | public-read ACL can fail on locked buckets (it warns) |
| MiniMax | 2.5 | Node runtime note, validation, env checks, sanitized key, deployment notes | Assumes the public URL works if bucket or CDN is configured |
| Codex | 2.5 | App Router, formData(), MIME and 5MB checks, PutObjectCommand | No empty-file check; public URL unexplained |
| Gemini 3.1 Pro | 3.5 | App Router, formData(), MIME and size checks, S3 upload | Env vars forced with !, no missing-env handling, no empty-file check |
| GLM | 4 | App Router, formData(), MIME and size checks, S3 upload | No env validation, no empty-file check, public URL assumption |
| Gemini 3.5 Flash | 4 | Correct pattern, MIME and 5MB validation, env vars, S3 upload | Empty-string credential fallbacks, no config validation |
| Kimi | 6 | Good validation coverage | Says busboy, then hand-rolls a fragile parser instead of request.formData() |
Lesson: Framework choice was solid. The risk moved into hardening: env validation, empty-file handling, and not assuming a public URL resolves.
Round 3: Which LLM Handled Password Reset Security Best?
Claude and MiniMax handled password reset security best because they covered token hashing, expiry, rate limiting, and safer reset-flow behavior.
Prompt We Used: A password reset flow with Express, Prisma, and PostgreSQL: a secure reset token, safe storage, expiry, anti-enumeration, a reset endpoint, password hashing, rate limiting, environment variables, Prisma fields, and a security explanation.
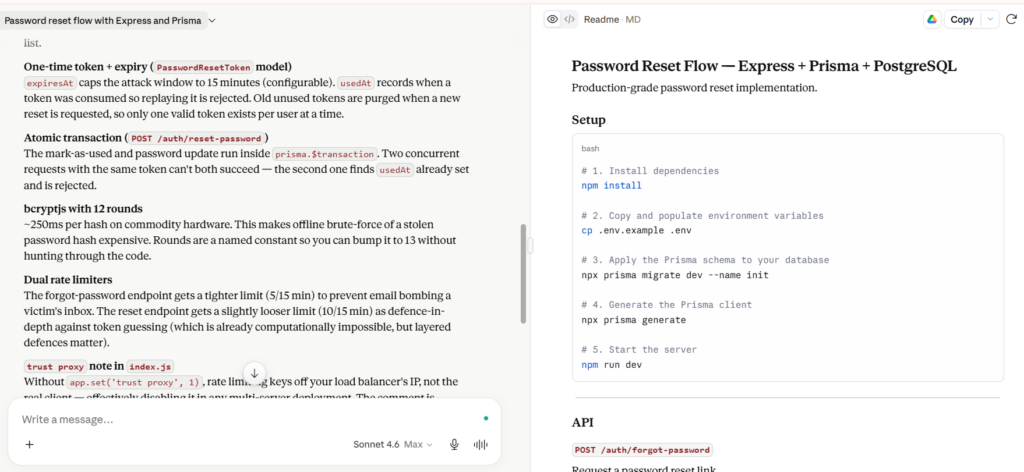
This round exposed the clearest gap between secure-sounding code and actually safer code. Claude and MiniMax produced the strongest security architecture: hashed tokens, expiry, one-time use, and rate limiting. Gemini 3.1 Pro gave a clean baseline.
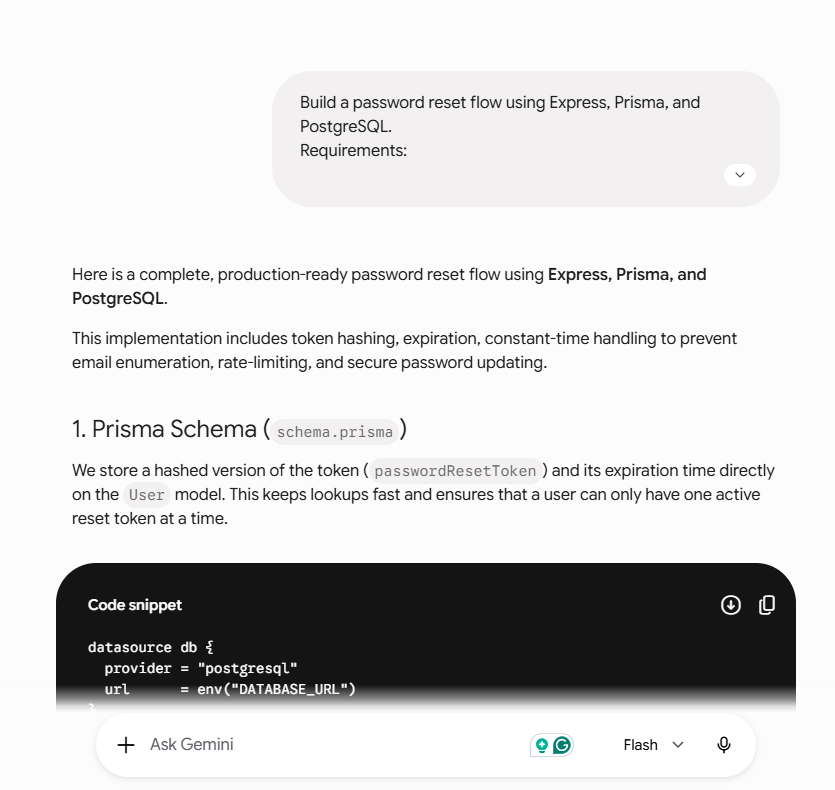
Gemini 3.5 Flash handled the core token flow but missed reset-endpoint rate-limit coverage. GLM and Kimi looked advanced but added complexity, copy-paste risk, or weaker race-safety than their explanations claimed.
| Model | Score | What worked | What failed or looked risky |
| Claude | 1.5 | Hashed tokens, expiry, usedAt, transactions, dual rate limiters, separate token records | Minor dependency cleanup |
| MiniMax | 1.5 | Hashed tokens, expiry, old-token invalidation, rate limiting, env validation | Optional token “peek” endpoint adds surface |
| Gemini 3.1 Pro | 2.5 | randomBytes(32), SHA-256 hashing, 15-min expiry, generic response, bcrypt, rate limiting | Slight timing-leak risk, mocked email |
| Codex | 3 | HMAC-SHA256 hashing, env validation, generic response, bcrypt, expiry | Email-fail for real users only can leak account existence |
| Gemini 3.5 Flash | 4 | Hashed, expiring tokens, anti-enumeration, password hashing | Reset endpoint lacks its own rate limiter |
| GLM | 5 | Good security concepts | Ships a broken crypto utility, then fixes it inline; adds an unneeded dependency |
| Kimi | 6 | Token hashing, expiry, email, bcrypt | Custom limiter references config without a clear import; less race-safe than claimed |
Lesson: The dangerous failure was not missing token generation. Most models got that right. The risk was confidence around incomplete rate limiting, email-failure behavior, and race-safety. If you build payment, auth, or multi-role logic, this is where custom software development and engineering review earn their place.
Round 4: Which LLM Hallucinates Least When Writing Reliable Jest Tests?
Claude and MiniMax produced the most reliable Jest tests, while Gemini 3.5 Flash had the shallowest coverage.
Prompt We Used: Jest tests for a pricing function, covering normal cases, quantity, discount behavior, cart total above 500, empty cart, and missing-validation risks.
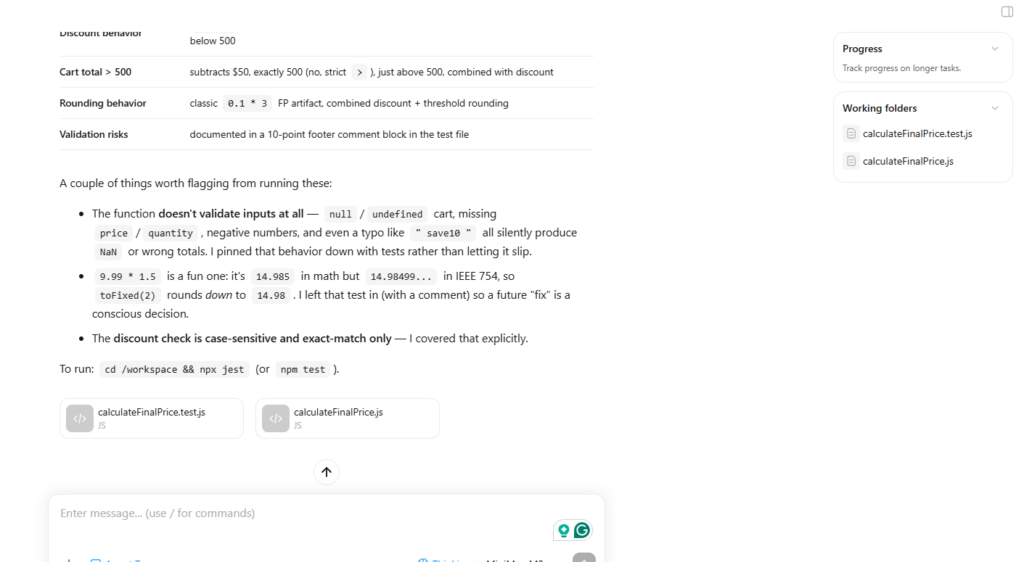
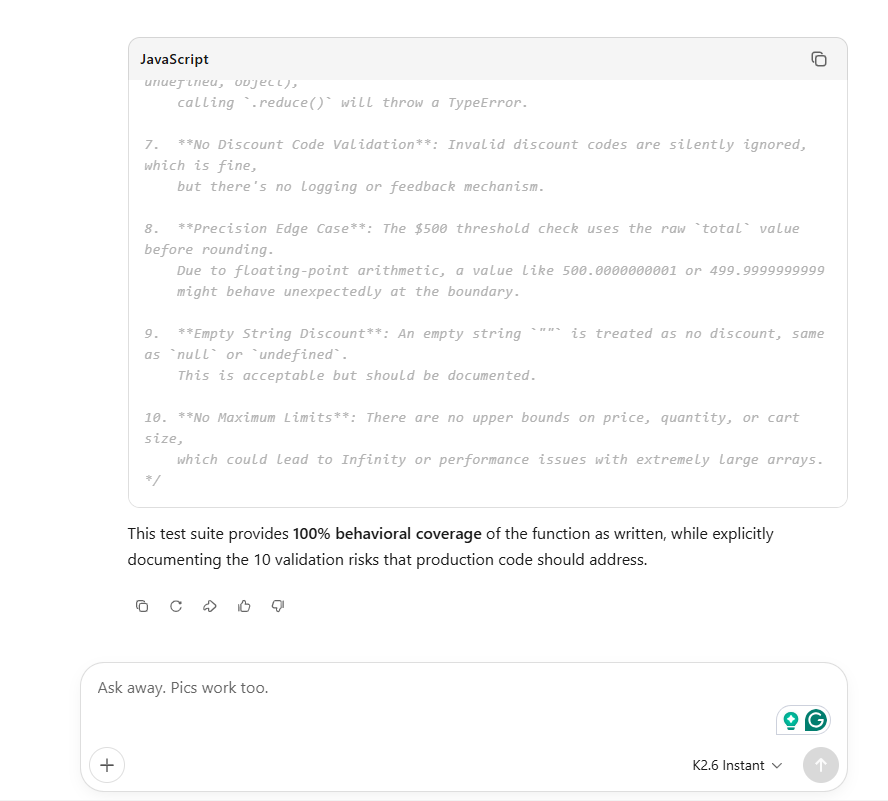
This round exposed false coverage confidence. Claude and MiniMax performed best because they treated it like a QA review, not a checklist. Gemini 3.5 Flash was weakest, covering basics but few edge cases.
| Model | Score | What worked | What failed or looked risky |
| Claude | 1.5 | Required cases, combined rules, rounding, validation risks; reran and fixed tests | Minor overconfidence |
| MiniMax | 1.5 | Ran the suite, caught a wrong expectation, fixed it, confirmed 23 passing | Minor overclaiming |
| Kimi | 2 | Deep coverage, many edge cases, 10 validation risks documented | Slightly overbuilt for a simple function |
| Codex | 3 | Normal totals, quantity, discount, threshold, combined rules, empty cart, rounding | Thinner validation-risk and edge coverage |
| GLM | 3.5 | Solid cases and validation notes | Defines the original function inside the test file |
| Gemini 3.1 Pro | 3.5 | Empty cart, quantity, decimals, discount, invalid codes, combined rules | Ships source plus tests despite “do not change the original function” |
| Gemini 3.5 Flash | 5 | Core cases: empty cart, quantity, discount, threshold, combined discount | Smallest suite; thin on validation risks |
Lesson: AI-generated tests can look complete while staying shallow. The best models tested rule interaction, rounding, and bad inputs, not just the obvious cases.
Final Ranking: Which LLM Hallucinated the Most While Coding?
GLM ranked highest by average hallucination risk, Kimi was riskiest in production-style implementation tasks, and Claude had the lowest overall risk.
- Claude (1.75), lowest overall risk. Strongest structure and security, with caveats included rather than hidden.
- MiniMax (1.88), strongest non-Claude performer. Full-project outputs and real self-verification in testing.
- Codex (2.75), clean and practical, less deep. Good shells and security, lighter edge coverage.
- Gemini 3.1 Pro (3.38), more reliable than Flash overall. Solid concepts, weaker packaging.
- Gemini 3.5 Flash (3.88), fast and clean but thinner on deeper security and testing.
- Kimi (4.25), riskiest in implementation-heavy tasks. Deep test coverage, but overcomplication drove a 6 and 6 in the build rounds.
- GLM (4.38), highest average hallucination risk. Good ideas undercut by messy, copy-paste-risky execution.
To be precise: GLM had the highest average risk score, so by the numbers it hallucinated the most. Kimi was the riskiest in the implementation-heavy rounds specifically. Both readings matter, and they point at different failure modes.
What Is the AI Confidence Gap in AI-Generated Code?
The confidence gap is when AI-generated code sounds production-ready while still missing security, persistence, validation, or test depth.
| Model | Confidence gap | Example from our test |
| Claude | Low | Flagged its own public-read ACL risk |
| MiniMax | Low-medium | Optional token “peek” endpoint and deployment assumptions |
| Codex | Medium | stripe: latest and handlers that log instead of act |
| Gemini 3.1 Pro | Medium | Shipped source plus tests when asked not to |
| Gemini 3.5 Flash | Medium-high | Production tone with TODO provisioning and credential fallbacks |
| GLM | High | 200 OK before processing; broken crypto utility fixed inline |
| Kimi | High | Fragile manual parser and a custom limiter missing its import |
OpenAI’s 2025 research ties this to training that rewards confident guessing over admitting uncertainty.
Dario Amodei, at Anthropic’s Code with Claude event in May 2025, framed the upside and the catch in one line: AI models “probably hallucinate less than humans, but they hallucinate in more surprising ways.”
What is AI Sycophancy, and How Does it Affect Code?
AI sycophancy makes code riskier because the model may optimize for a confident, agreeable answer instead of exposing uncertainty or gaps.
In April 2025, OpenAI rolled back a GPT-4o update it called “overly flattering or agreeable,” a behavior it described as sycophantic.
The company said new reward signals based on user thumbs-up had weakened the checks that held sycophancy down, so the model skewed toward answers that were supportive but disingenuous. Sam Altman called the update “too sycophant-y and annoying” before the rollback.
We saw the coding version of this in every round. Models declared shells production-ready, claimed full coverage, and described security the code did not implement. None of it was hostile. It was eager. The fix is not a better mood from the model. It is review that does not care how confident the output sounds.
What Do Developers Say About AI Hallucinations in Coding?
Developers still use AI coding tools, but their main concern is almost-right code that takes extra review to trust.
The 2025 Stack Overflow Developer Survey shows the same split. AI adoption reached 84%, but only about 3% of developers said they highly trust AI output. More developers distrust AI accuracy than trust it, and the top frustration, cited by 66%, was AI answers that are “almost right, but not quite.
Reddit discussions around AI coding show the same pattern.

- In r/technology, engineers describe being handed AI-generated code that technically works but still needs cleanup, review, restructuring, and de-risking before it belongs in a real codebase. The frustration is not that AI cannot generate code. It is that the review burden moves to senior engineers after the code already looks finished.
- In r/vibecoding, non-developers ask the harder question: how do you know the AI is hallucinating if you cannot read the code? The strongest answers point back to the same controls we used in this test: small tasks, code review, tests, official docs, and someone technical enough to know what “clean” means.

- In r/BlackboxAI_, the mood is more pragmatic. Developers do not reject AI coding tools outright. They treat hallucination as the cost of speed. The safer workflow is narrow tasks, small diffs, test coverage, and asking the model to explain changes before accepting them.
Why did AI Hallucinations Become a 2026 Search Trend?
Public cases moved AI hallucinations from theory to professional risk, so people started searching for what it is and how to catch it.
The legal example: in April 2026, the law firm Sullivan & Cromwell apologized to a New York bankruptcy judge after an AI-assisted filing carried roughly 40 fabricated or wrong citations.
A 2026 audit by Zhao and colleagues estimated 146,932 hallucinated citations in scientific papers published in 2025 alone.
The searches around this fall into a pattern:
- AI checker: people want detection, but AI checkers flag AI-written text. They do not verify whether code is technically correct.
- AI agent: grounded agents with tools reduce some errors, but weak agents automate mistakes faster.
- Generative AI and LLM hallucination: hallucination is a broad generative AI problem.
How Should Software Teams Verify AI-Generated Code?
AI coding tools speed up work, but they are not production engineers. The stakes are rising: Microsoft’s Satya Nadella said 20% to 30% of code in some company repos is now written by AI, and Google’s Sundar Pichai said more than 25% of new code at Google is AI-generated and then reviewed by engineers. More AI code means more review, not less.
Practical checks from the test:
- Verify API references against official docs.
- Run the generated code.
- Check the framework version and routing patterns.
- Review secret handling, token storage, and expiry.
- Validate rate limiting on every sensitive endpoint, not just the obvious one.
- Check whether tests cover rule interaction, not only happy paths.
- Treat “production-ready” claims as unverified.
- Require senior engineering review before merge.
A generated feature is not launch-ready software. Closing that gap is the work a mobile app development team does after the model stops.
The Bottom Line
No model in this test clearly invented fake Stripe or AWS APIs. The bigger risk was harder to catch: code that sounded finished while security, persistence, business logic, or test depth was still missing.
GLM had the highest average risk score at 4.38. Kimi was riskiest in implementation-heavy rounds, scoring 6 on both the upload and password reset tests. Claude had the lowest risk at 1.75, with MiniMax close behind at 1.88.
The ranking matters less than the pattern. The weakest outputs were confident about unfinished work. That confidence gap is what makes AI-generated code dangerous in production.
AI can write the first draft. Verification still belongs to the engineering team.
Table of Contents
Frequently Asked Questions
An AI coding hallucination is when a model invents a method, package, event name, config, behavior, or security guarantee that does not exist and presents it as correct. A normal bug misuses a real tool. A hallucination invents the tool.
The usual ones are a fake SDK method, a wrong framework pattern, "production-ready" code with TODO business logic, a security note that claims token hashing while the code stores the raw token, and a test suite that reports full coverage but skips combined logic. The riskiest examples look correct until review.
Because they are trained to produce confident, plausible output, and confidence is not correctness. OpenAI's 2025 research found that training and evaluation often reward a guess over admitting uncertainty, so models sound sure even when business logic, security, or tests are missing.
GLM had the highest average hallucination risk in our test, at 4.38 out of 10. Kimi was the riskiest in implementation-heavy tasks, scoring 6 on both the Next.js upload and the password reset.
Claude, at an average of 1.75 across all four rounds. MiniMax was the closest runner-up at 1.88, making it the strongest non-Claude performer.
Flash produced a cleaner first output in the Stripe round, but 3.1 Pro was more reliable overall, with a lower average hallucination risk score across the four tasks.
Verify API references against official docs, run the generated code, check framework versions, review security and token handling, confirm tests cover rule interaction, and treat any "production-ready" claim as unverified until a senior engineer signs off.
Related Articles
No related posts found.
Value we delivered
82%
Reduction in processing time through our AI-powered AWS solution
View the case studyLaunch Faster Without Hiring Delays
Add senior engineers to your team in days. 150+ deliveries, 90% retention, and week-1 PR targets.